Introduction to Cassandra for SQL folk
"Where we're going, we don't need foreign keys!"
Apache Cassandra has become a bit of a staple amongst some of the most ambitious and data-heavy companies, with notable users including Netflix, Uber and Apple.
It solves lots of the problems typically faced by teams building “always on” services for millions of highly-engaged customers.
In other words, Cassandra is a powerful tool for when your data problems can’t be solved by a single machine — either because you have too much data, too many people need to access it at once, or the cost of it being unavailable for a while (should your single machine catch on fire 🔥) is too high.
At Monzo, we store almost all of our data in Cassandra. From temporary non-critical data such as application logs, to account details and other important data.
Motivation for writing this article
Prior to joining Monzo, I’d worked almost exclusively with relational databases such as PostgreSQL and MySQL. I wanted to get a better understanding of Cassandra’s data-model and how it differs from a more traditional SQL database, so I read the academic paper which, though enjoyable, left me with even more questions.
Ultimately, I felt I was lacking a clear mental model or intuition about how to structure data to make the most of Cassandra’s unique capabilities. Something which felt very natural to me with the relational model.
In this article I hope to share that intuition with you, and to give you a few practical tips to avoid some of the most common pitfalls along the way.
What’s so good about Cassandra, anyway?
Often when comparing databases, people use intangible phrases like “scalable” or “fault-tolerant” — and of course both of these can be applied to Cassandra, but without a better understanding of how a system does the things it’s good at, it’s hard to fully understand what it’s bad at.
Cassandra allows you to store enormous amounts (think petabytes) of data, by splitting it up across multiple machines.
It keeps that data available to your users even in the face of failing hardware, unreliable networks, even losing an entire datacenter or geographical region by keeping multiple copies on different machines.
Finally, contrary to many distributed data-stores where different machines have special roles (e.g. “leader” and “follower”) in Cassandra every machine is basically identical, meaning you can scale your cluster linearly with your data by simply adding more of them.
Cassandra is also particularly good at write-heavy workloads, due to the efficient way data is stored on disk, but we won’t cover that in this article.
Our objective
We’re going to get to grips with the practical implications of Cassandra’s design choices by designing a database for an online marketplace. 🛍
Our schema will comprise of products listed by merchants.
Old familiar tools
Let’s see how it would look when modelled using PostgreSQL a popular relational database. Our data is arranged into tables, where each record is a row with its values stored in different columns.
CREATE DATABASE marketplace;
-- psql: \c marketplace
CREATE TABLE merchants (
id varchar,
name varchar,
PRIMARY KEY (id)
);
CREATE TABLE products (
id varchar,
sku varchar,
title varchar,
merchant_id varchar,
price_pence int,
PRIMARY KEY (id)
);
Using SQL we can interact with our data in lots of useful ways, perhaps the most straightforward being grabbing a record by its “primary key”:
SELECT * FROM merchants WHERE id = 'merch_0001';
We can also find records using other columns. For example, we store an SKU (Stock Keeping Unit) against each product, which is like a special reference uniquely identifying it across all of a merchant’s different systems.
SELECT * FROM products WHERE sku = 'BLUE_LARGE_HAT';
Two products should never have the same SKU and we can even have our database enforce this constraint for us using a unique index.
CREATE UNIQUE INDEX uniq_products_sku ON products (sku);
INSERT INTO products (id, sku, title)
VALUES
('prod_0001', 'BLUE_HAT_LARGE', 'Blue Trilby'),
('prod_0002', 'BLUE_HAT_LARGE', 'Blue Beanie');
ERROR: duplicate key value violates unique constraint "uniq_products_sku"
We can also do different kinds of aggregations on our data. Say, for example, we wanted to find the price of the most expensive product:
SELECT MAX(price_pence) FROM products;
Finally, we can model the relationships between records in our database using “foreign keys” and “join” across them in queries.
Using foreign keys enables the database to ensure the referential integrity of our data. Our products table should never contain a merchant_id which doesn’t map to a record in the merchants table, and with the foreign key constraint in place the database won’t allow it.
ALTER TABLE products
ADD CONSTRAINT fk_products_merchant
FOREIGN KEY (merchant_id) REFERENCES merchants;
SELECT merchants.name, products.title
FROM merchants
INNER JOIN products
ON merchants.id = products.merchant_id;
How does Cassandra stack up?
Our relational tools give us an intuitive, familiar way to model our data and the relationships between it. So how does Cassandra compare?
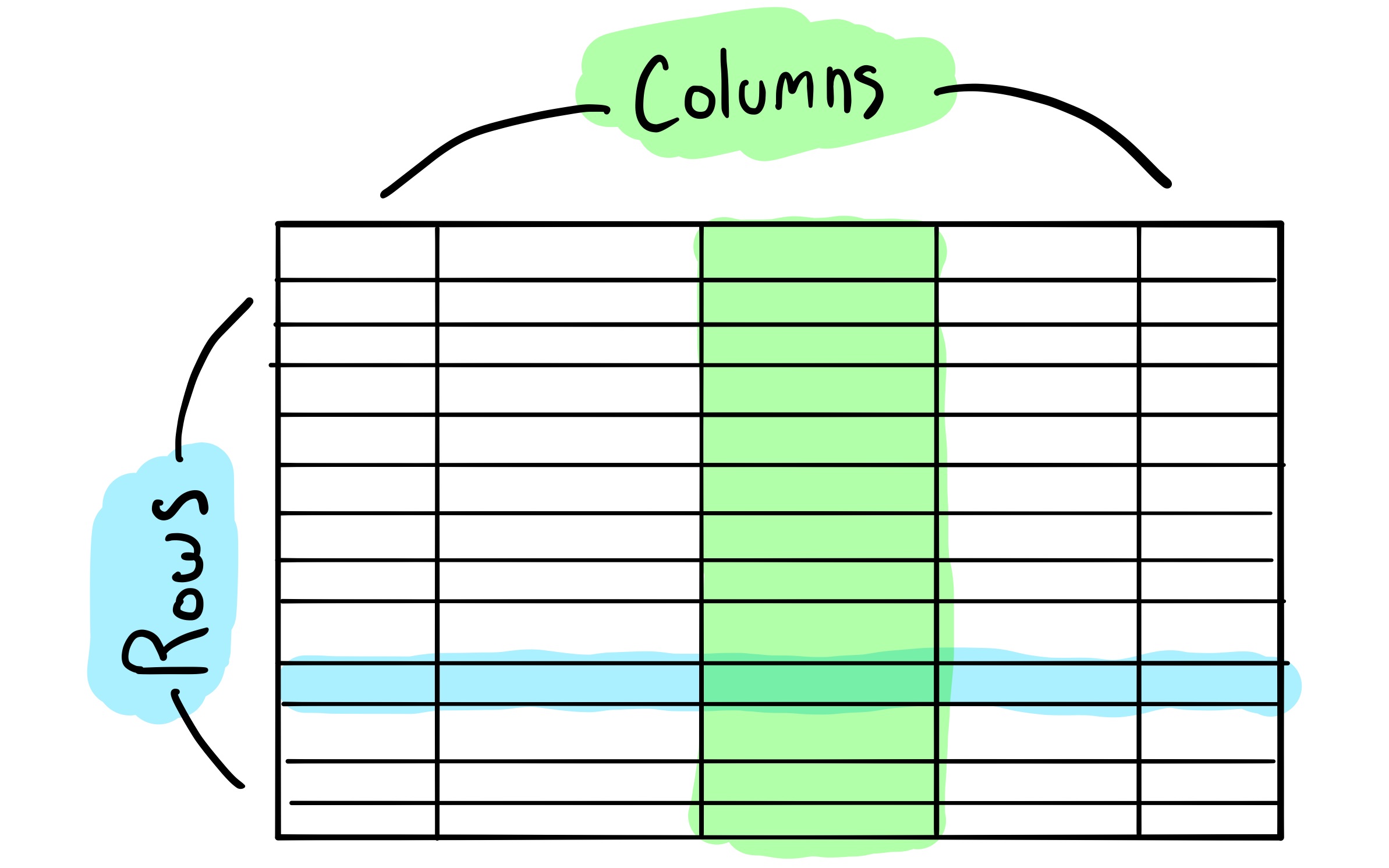
On the surface, Cassandra feels very familiar. Using CQL we’re able to model arrange our data into tables, rows and columns as we would with a traditional SQL database — this may however be where the similarities end.
Earlier in this article I mentioned that Cassandra makes it possible to store humongous amounts of data by splitting it up across multiple machines. It does this by splitting tables into smaller groups of rows called partitions, which as we’ll shortly see has profound practical implications for how we model our data.
Let’s start by copying our relational schema verbatim:
CREATE KEYSPACE marketplace WITH replication = {
'class': 'NetworkTopologyStrategy',
'datacenter1': '3'
};
USE marketplace;
CREATE TABLE merchants (
id varchar,
name varchar,
PRIMARY KEY ((id))
);
CREATE TABLE products (
id varchar,
sku varchar,
title varchar,
merchant_id varchar,
price_pence int,
PRIMARY KEY ((id))
);
Aside from swapping the word “database” for “keyspace” and configuring how our data will be replicated amongst the cluster, our schema definition is basically identical.
Let’s try a few of the queries, starting with reading by primary key:
SELECT * FROM merchants WHERE id = 'mc_12345';
That seems to work okay! Which is a relief. 😊
How about reading by a different column?
SELECT * FROM products WHERE sku = 'BLUE_LARGE_HAT';
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
Uh-oh. Looks like we can’t do that without turning on an option which will result in “performance unpredictability” whatever that means. 🤔
Let’s try the aggregation:
SELECT MAX(price_pence) FROM products;
(1 rows)
Warnings :
Aggregation query used without partition key
Well it seems to work, but that warning message doesn’t fill me with confidence. 😕
How about joining tables together?
SELECT merchants.name, products.title
FROM merchants
INNER JOIN products
ON merchants.id = products.merchant_id;
SyntaxException: line 3:0 missing EOF at 'INNER'
Oh, it looks like joins aren’t supported in Cassandra at all! 😰
What’s going on here? Why can’t Cassandra serve these seemingly straightforward queries?
It’s all to do with partitions.
If no single node in our cluster has a full view of the entire table, we’re going to have to query many nodes (possibly thousands in a larger cluster) to find the data we need, which could be incredibly expensive.
That is of course, unless we can write queries that target specific partitions instead. In other words: if we can store data that we need to read together in the same partition, our queries can be served by a much smaller (and fixed) number of nodes.
Similarly, ensuring uniqueness, referential integrity and performing joins can be expensive when data is scattered around the cluster in different partitions (and in some cases require complicated coordination techniques such as distributed locking) so if we care about these things we’ll need to implement them ourselves in application code.
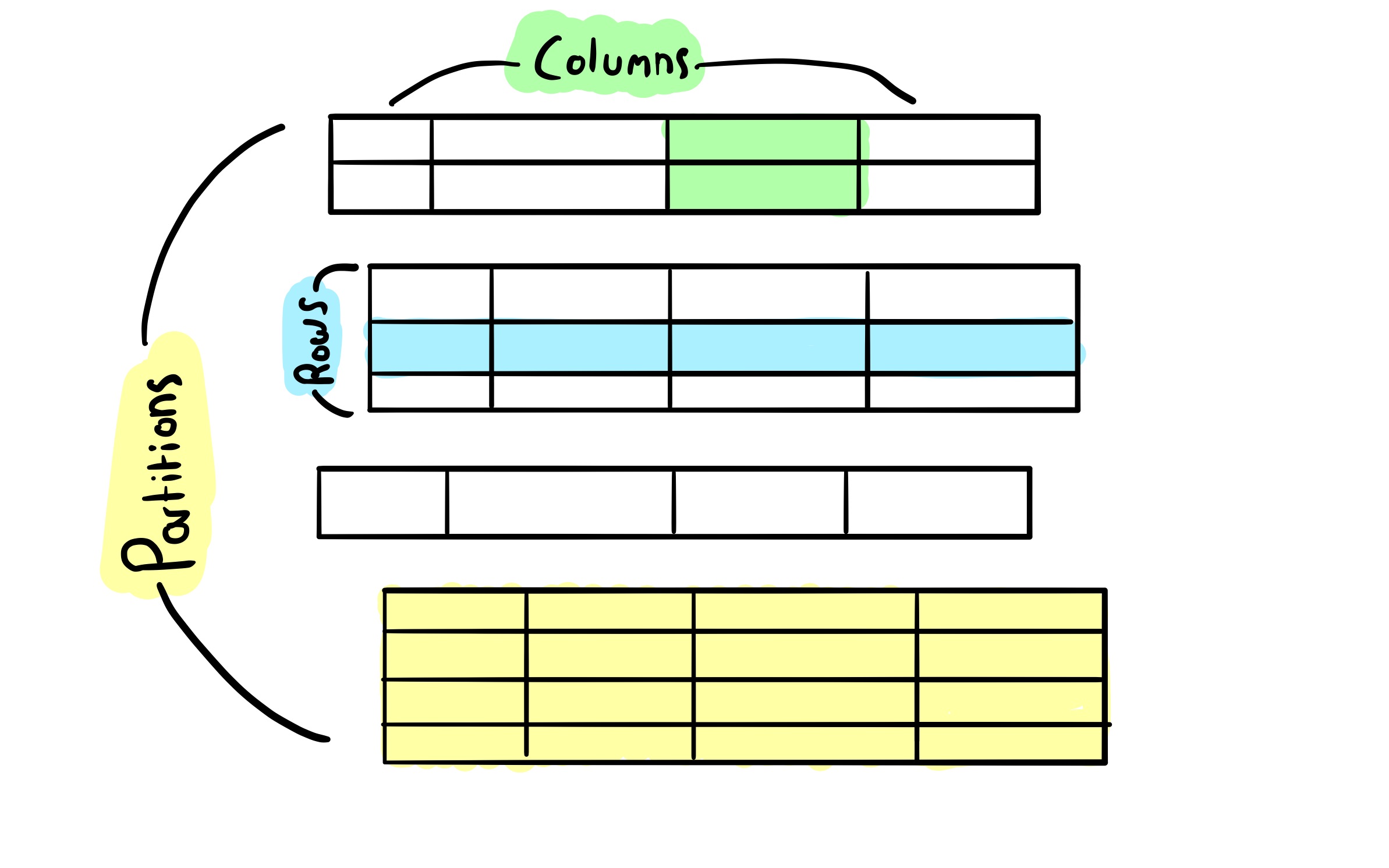
Working with partitions
So how do we control which partition our data ends up on? The answer is by changing our primary key.
Whereas primary keys in relational databases are mainly used to uniquely identify rows, in Cassandra they have a couple of other additional purposes.
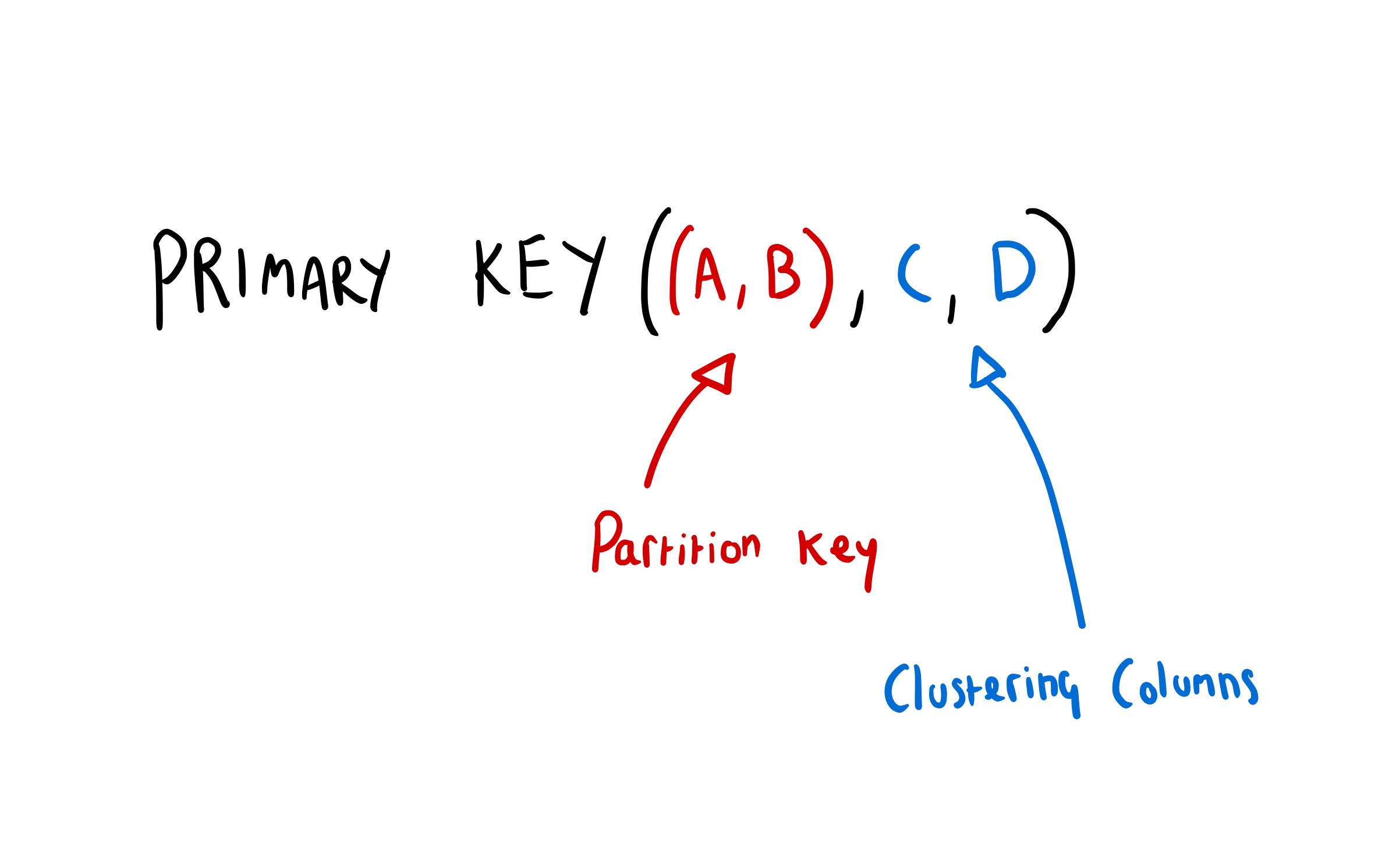
Cassandra’s primary keys are made up of two parts. The “partition key” which decides which partition a row will live on, and the “clustering columns” which determine how rows will be ordered (or “clustered” together) within a partition, on disk so that they can be read efficiently.
Going back to our “reading by SKU” example. In order to be able to read products by both the id column and the sku column we must store multiple copies of our data in separate tables, partitioned by different columns.
CREATE TABLE products_by_id (
id varchar,
sku varchar,
title varchar,
merchant_id varchar,
price_pence int,
PRIMARY KEY ((id))
);
CREATE TABLE products_by_sku (
id varchar,
sku varchar,
title varchar,
merchant_id varchar,
price_pence int,
PRIMARY KEY ((sku))
);
This is known as “denormalisation” and it’s a pretty common pattern for speeding up database access in high-traffic applications, but it doesn’t come for free and we’ll discuss some of the trade-offs later in this article.
I think this highlights perhaps the biggest difference between data-modelling with a SQL database compared and with Cassandra. In a relational database your priority is often to build a data-model that most resembles the real-world domain objects and concepts of your application, but in Cassandra your chief concern is how the data will be used.
On a practical note, I personally find it helpful to think of Cassandra less as a tabular datastore and more as a key-value store (like a the map data structure available in most programming languages). If I want to find a value (row) by two different columns, then I must store it against two different “keys”.
Handling time-series data
Let’s imagine that we want to store the orders made through our marketplace, and each day we’ll aggregate them to find out the total amount of money we’ve made.
In a relational database we’d likely add a timestamp column, giving us a to-the-microsecond record of when the order took place, and use this to find results for a given day.
With Cassandra, we need to partition our rows such that they can be efficiently read and aggregated — so the solution is to partition them into time buckets (e.g. a partition for each day) enabling us to read all of the data we need from a single node.
CREATE TABLE orders (
id varchar,
amount_pence int,
timestamp timestamp,
day int,
PRIMARY KEY ((day), timestamp, id)
);
INSERT INTO orders (id, amount_pence, timestamp, day)
VALUES ('ord_0001', 1000, '2020-01-01T12:30:00Z', 20200101);
INSERT INTO orders (id, amount_pence, timestamp, day)
VALUES ('ord_0002', 4000, '2020-01-01T14:12:00Z', 20200101);
SELECT SUM(amount_pence) FROM orders WHERE day = 20200101;
Gotchas
Now that we’ve got an understanding of the basic form our data will take, let’s dig into some of the common pitfalls we’ll need to avoid when using Cassandra in practice.
Hot and wide partitions
Partitions allow us to split our data, and the work of querying and aggregating it, between multiple nodes — but not all partitions are created equal.
Imagine that we partitioned our products table by merchant_id. What would happen if one merchant became an overnight success or ran a flash sale, generating an inordinate amount of load on our cluster? The handful of nodes responsible for serving that partition would bear the brunt of it, and potentially get overwhelmed at a time when they most need to be available.
Further, our day-bucket partitioning scheme for orders works well now, but as our business grows we may run into issues from having increasingly large partitions. In fact, once a partition becomes larger than 100mb Cassandra will begin to log warnings, as it puts a lot of pressure on the JVM heap, so as a rule of thumb at Monzo we try to keep our partitions smaller than 30mb (which requires careful planning based on the estimated frequency of writes, and how big each row will be).
Choosing a partitioning scheme is a fine art, and something you probably won’t get right first time. Having a good understanding of your data and how it will be accessed is vital to keeping your data-model flexible and scalable.
Note: you may also hear this problem described as having a hot or wide row. Prior to the introduction of CQL, in the old Thrift API, the terms “row” and “column” were used slightly differently, it’s the same concept, though.
Dropping ACID
Most relational databases offer some form of ACID guarantees. ACID is quite a broad and nuanced topic, but the parts we’re interested in, which Cassandra largely eschews, are Atomicity and Isolation.
In short, relational databases allow us to group operations into “transactions” where either all of them succeed, or they all fail, there is no possibility of partial failure (Atomicity). It’s also not possible for another client to read only some of a transaction’s writes (Isolation).
Given that we need to maintain multiple (denormalised) copies of our data, it’d be very helpful to be able to make changes atomically and in isolation of other transactions, but in a distributed system this is very hard, so it’s not something Cassandra supports (though newer distributed databases such as CockroachDB and YugabyteDB do offer some of these stronger guarantees).
In practice this means that you need to very carefully consider how you will handle if only some of your writes succeed, and your tables get out-of-sync. For this reason, at Monzo we often don’t store full denormalised copies, but instead use mapping tables (e.g. merchant_id_to_product_ids) and incur the overhead of doing multiple reads for better data consistency.
What we didn’t cover
There’s so much more to Cassandra than could be covered in a brief(-ish 🤞) article.
I chose to focus on the key data-modelling ideas that tripped me up as somebody coming from relational databases, and skipped other important topics such as tunable consistency or what exactly a “tombstone” is.
If you’d like to learn more about Cassandra, I’d recommend check out the DataStax docs, blog and their other helpful resources.